Author profile
Scott Edmunds
GigaScience Press Wins Inaugural Crossref Metadata Award
Scott Edmunds - May 10, 2025

GigaScience Press’ has been awarded one of the first CrossRef MetaData Awards, highlighting the Press as a leader in providing essential information to facilitate discovery, identification, and details of online research articles. This week GigaScience Press has been announced as a winner at the inaugural Crossref Metadata Awards, recognising efforts in scholarly publishing metadata completeness […]
Where we are in the T2T Genomes Era, Pt 2. T2T Sex Chromosomes
Scott Edmunds - May 7, 2025

Following our previous DNA Day 2025 post covering where we are in the T2T (telomere-to-telomer) genomes era, we have a second expert Q&A covering the topic, this time from Kateryna Makova on the challenges (and opportunities) of assembly of T2T sex chromosomes. Lets Talk about Sex Chromosomes Kateryna Makova is the Verne M. Willaman Chair […]
DNA Day 2025: Where we are in the T2T Genomes Era, Pt 1
Scott Edmunds - April 25, 2025
Today is International DNA Day, commemorating the day in 1953 when Crick, Watson, Wilkins and Franklin published their papers on the structure of DNA. Fifty years later, with the declaration that the human genome project was close to completion the US Senate and the House of Representatives declared that 25th April 2003 would be the […]
Open CycloneSeq Benchmarking For Complete Bacterial Genomes
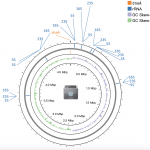
As another DNA Day treat GigaByte today publishes new benchmark data and analysis of the new CycloneSEQ platform, a novel sequencing technology using nanopores that demonstrates here the ability to sequence complete bacterial genomes. Following on from the recent official launch of BGI’s new CycloneSEQ single-molecule sequencer the new Data Release published today in GigaByte […]
DNA Day 2025: Mission Accomplished for Bauhinia Genome
Regular readers may have followed our community genome project Bauhinia Genome, and today marks the end of this journey with the publication in GigaScience of completely gapless telomere-to-telomere (T2T) genome assembly which helps advance our understanding of the genomic structure underlying the captivating traits of Hong Kong’s floral emblem. The 25th April is International DNA […]
From Social to Biological Networks: A New Algorithm Uncovering Key Proteins in Human Disease
Scott Edmunds - April 9, 2025

Published today in GigaScience is a new algorithm connecting social and biological networks to identify key proteins in Human Health. Researchers at Ben-Gurion University of the Negev have developed a machine-learning algorithm that could enhance our understanding of human biology and disease. The new method, Weighted Graph Anomalous Node Detection (WGAND), takes inspiration from social […]
Extended call and webinar for GigaByte’s vectors of human disease series
Scott Edmunds - April 5, 2025

Regular readers will have heard the news that TDR, the Special Programme for Research and Training in Tropical Diseases, GBIF and GigaScience Press have announced a third call for authors to submit Data Release papers on vectors of human disease for inclusion in a thematic series published in GigaByte Journal. Thanks to additional support from […]
From Social-Media to Protein Networks: join our Cassyni webinar on algorithm based detection of diseases
Scott Edmunds - April 2, 2025

GigaScience Press is pleased to announce an upcoming Cassyni webinar on algorithm based detection of diseases using AI-based approaches taken from social media to protein networks. Hosted by GigaScience Editor in Chief Scott Edmunds and featuring a chance to ask questions, this free online webinar using the Cassyni platform will be on April 8th at […]
Publish Peer-Reviewed Protocol Papers with Protocols.io and GigaByte
Scott Edmunds - January 30, 2025
This week we are pleased to announce and highlight new updated additions to our long-running collaboration with protocols.io, linked to our first paper with a peer-reviewed protocol featuring a “Peer-reviewed method” badge on protocols.io. Alongside the addition of new functionality in protocols.io to submit protocols as method papers to GigaByte. The new GigaByte paper presents […]
Crossing the Open Science Streams: Cassyni X Sciety (and GigaByte) FTW
Scott Edmunds - January 8, 2025

Innovation + Integration = Cassyni X Sciety As an Open Science publisher, we’ve written extensively on our aims to think and act wider to better address the UNESCO Open Science Recommendation. Particularly the key pillars of “Open Engagement of Societal Actors” and “Open Dialogue with other Knowledge systems” where we need to improve the inclusiveness […]