Gigantum Joins the Giga Reproducibility Toolkit
GigaScience has always had a focus on reproducibility rather than subjective impact, and it can be challenging for our reviewers to judge this, especially now that more and more tools are being created – bringing data science to the masses. This also means more efficiency and ease is required especially when multiple collaborators and contributors on a specific project are involved. As a journal with an ethos on reproducibility, we also think about our reviewers – are they able to test and run the tools easily as part of peer review?
Moving from experimenting with our GigaGalaxy.net server, Virtual Machines, and Docker containers, GigaScience has been using Code Ocean to bring much of this experience together in a platform that lets you scrutinise code, test it and then run it on your own cloud computing account, if it is of interest. In addition, new tools have been created to make the research article itself executable and reproducible – GigaScience Press is now collaborating with Stencila in a new ERA (Executable Research Article).
Working these tools into the review and publication process potentially makes it easier to assess replicability and utility. However, we have experienced some hurdles in carrying out reproducibility case studies (see this example published in PLOS One) and getting our in-house data scientists involved in the review process– one paper costing us over $1500 USD in AWS credits to recreate the workflows. Given that collaboration and reproducibility often requires working across different infrastructures and contexts; for example, laptop, GPU, on premises infrastructures and public cloud, problems can arise as most commonly used cloud-based Software as a Service (SaaS) infrastructures make it difficult for collaboration, and can involve a huge monthly cost on cloud credits – as we have experienced.
Joining our Giga reproducibility toolkit is Gigantum, an open source (MIT licensed) web application that aims for better collaboration, sharing and making reproducible research easier. However, what makes it different is that the Gigantum workbench can be run anywhere (laptop, GPU, on premises infrastructures, and Public Cloud) – eliminating problems that can arise when collaborating via multiple infrastructures and contexts are involved. In addition, Gigantum is not purely SaaS dependent and thus is potentially cheaper (with not having to rack up cloud credit costs) – the platform allows users to cut the corn on cloud-only platforms. Tyler Whitehouse, CEO of Gigantum, along with Dean Kleissas and Dav Clark (previously Head of Data Science at Gigantum, and now Director of Glass Bead Labs), shared their views in an earlier blog about “Making Reproducibility Reproducible” in a Guest Post in GigaBlog. They highlighted the need for better reproducible research, focused on user experience, and ease of use.
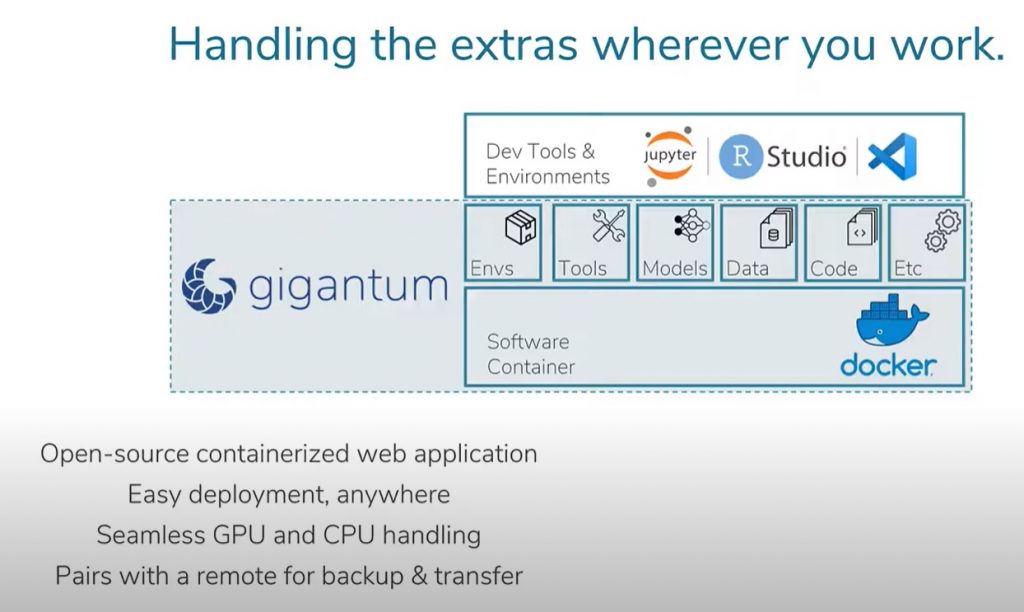
GigaScience has been seeing a lot more complex tools utilizing machine learning, and to help with reproducibility with machine learning-based tools, Gigantum is a great platform to share the fruits of these, with a collection of examples of many common AI and machine learning tasks that users can copy and customize. As we are always on the lookout for new platforms to test and integrate into our open science workflow, it was a no brainer to try and integrate Gigantum with our open peer review.
The latest paper, published in GigaScience – Driftage, is our first paper having utilised the Gigantum platform as part of our open peer review, and reviewed by Dav Clark. Since Driftage is a more complex machine learning framework and with the added complexity of being multi-agent based, this meant it was more difficult for the authors to ensure reproducibility, since each agent is independent on results; and thus, dynamic due to when each agent communicates with others and a particular environment at a particular point in time. Given this complexity, Driftage seemed to be the right paper to ensure its reproducibility using Gigantum. In addition, Figure 5 of the manuscript was also reviewed for reproducibility, via CODECHECK, and the paper is our second example, and overall 24th paper given a certificate of independent execution (see the new paper in F1000Research). You can also read more about CODECHECK and our first example, in our blog on Certified Reproducibility. As huge fans of citable DOIs, another added bonus is that the Driftage project in Gigantum has a citable DOI that can be cited in future papers.

Here, we have a Q&A with the Driftage lead author, Diogo Munaro Vieira who shares his user experience on Gigantum and the benefits of having a reproducible environment for machine learning tools.
Q: Despite the editorial’s suggestion to try it- what made you agree to try the platform?
The Gigantum platform helps a lot with the reproducibility of my figures and tables. In the case of Driftage it was very easy because I just needed to install the Driftage library in the Gigantum Jupyter environment and reproduce the results. Now it’s simple for anyone who wants to get the same result without installing the whole environment.
Q: What did they like about Gigantum? Did you find it easy to use?
It’s easy to use because it has a very intuitive user interface and integration with git. So, my collaborators that are not comfortable with the git interface can make changes and see results using the Gigantum user interface. The best feature I saw was that when you run the Jupyter notebook and build new results, it recognizes that a new figure or table was created and automatically adds it to your results. It’s kind of magic!
Q: Can you tell us more about the Driftage tool and what benefits do you see having a reproducible environment in Gigantum?
Driftage is a modular multi-agent framework to detect concept drifts from batch or streaming data. It was made with Python and it is available as a library that users can install and start building their concept drift detectors. As a framework it’s important to be reliable and retrieve reproducible results. Driftage was very hard to enhance a reproducible environment because of its multi-agent nature where each agent is independent to decide your own results; and results can change depending when each agent communicates with others and how the whole environment is at that moment. Another point is that electromyography (EMG) data should be analyzed as streaming data and it is a very good data type for drift detection algorithm, since most of the time, what changes is the variance of the data and not the spikes. So, the data drift is very hard to detect just by looking. In the Driftage example we chose the ADWIN algorithm that captures data variance changes very well. Gigantum forces me to isolate each part of the architecture to guarantee reproducibility on them removing the environment and communications noises and making EMG streaming data static for reproducible analysis.
Using Gigantum for future work on Driftage should be simple because a person just needs to install the library and implement their algorithm for drift detection with their own data. Because of multi-agent nature they need to evaluate each part of their own implementation separately and validate using Gigantum with a static sample of data or generate data using a data generator.
Q: How do you see Gigantum ensuring reproducibility of your work?
Gigantum is very efficient at reproducing the work because it makes sure that all the environment and dependencies will be the same. Of course, as users, we need to put the correct version of extra dependencies in our work avoiding some dependency updates and crash results, but the base project is always the same environment. The CODECHECK process was so good because a reviewer needed to understand and run my code (see the resulting certificate). It was an enriching process because I needed to make some changes in my current work, so that it is easy to run and reproduce.
Q: Why do you think Gigantum was useful for this type of machine learning work?
More and more machine learning work needs explainability and interpretability of its results because of privacy rules. The first step for explainability and interpretability is reproducibility, where in which Gigantum helps a lot. Another important collaboration of Gigantum for machine learning work is the comparison with other works. When someone makes a better algorithm to solve a problem, it needs to prove that the machine learning algorithm is really better and Gigantum isolates the environment for a fair comparison that will be available for everyone who wants to check. Driftage was an example algorithm with ADWIN that we need to prove it’s impacted by variance to make sure the framework was not changing algorithm behavior.
Further reading and playing:
- Diogo Munaro Vieira, Chrystinne Fernandes, Carlos Lucena, Sérgio Lifschitz, Driftage: a multi-agent system framework for concept drift detection, GigaScience, Volume 10, Issue 6, June 2021, giab030, https://doi.org/10.1093/gigascience/giab030.
- Diogo Munaro Viera, Chrystinne Fernandes, Carlos Lucena, Sergio Lifschitz (2021): Driftage Example: A Multi-agent Drift Detection Framework, Gigantum, Inc https://doi.org/10.34747/mp7n-3487