Big Data Challenges and Solutions in Contemporary Ecology: A Guest Blog by Chris Lortie

The great responsibility
Every discipline of science is unique. Ecology is no exception. We work in diverse, complex, context-dependent systems. Global change and anthropogenic influences are very real issues for the health of the planet that ecologists often examine. As a discipline, we have moved from context-dependent, local studies to much larger, integrated studies. Collaboration is critical and increasingly common within our field (Nabout et al. 2015), and addressing change at much larger scales has been a major innovation in the last ten years. With larger teams and increased scales of study, ecology has crossed the big data threshold (Hampton et al. 2013) and with that power, has come great responsibility and new challenges to our discipline. Here is a brief summary of two challenges and associated solutions.
Context Dependency
Ecology is the study of interactions (typically biotic-biotic-abiotic). Specifically, we study biotic components – typically organismal or higher organizational levels – interacting with other biotic organisms and/or the environment. The more interactors the better in many respects, but the scaling and necessary levels of replication to do fully orthogonal experiments can limit our capacity to examine the extents of players within a system that we might prefer. Contemporary ecology is a synthesis or mashup of natural history including descriptions of place and species often in great detail and the increasingly relevant and importance of scale and inference. A common historical criticism of ecology was that every reported interaction was context dependent. The advantage of this viewpoint is that we can use it to our advantage to define when interactions are context dependent such as invasion by exotic species (i.e., see the work of Carla D’Antonio) and potentially manage to avoid these contexts. However, the dynamic tension between the local and the regional or any set of contexts such as field versus lab is a set of real challenges. Perhaps the most compelling solution was a recent meta-analysis using extensive aggregated data to explore the importance of variation, i.e. context, directly and not chase the mean value of interactions (Chamberlain et al. 2014). This transformative approach using synthesis would not be possible without open data within ecology. Consequently, synthesis in ecology is increasingly critical to explore the relative value of considering context versus increasing the scale of both fieldwork and data aggregation. There is an ‘art’ to this process, but the reward is much greater reach to the more general, contemporary work that acknowledges context but examines larger scales (Lortie and Bonte 2016). The challenge we faced and continue to embrace that is relatively unique to our scientific field is context and the solution is synthesis.

Photo from Chris Lortie
However, data sharing continues to be a challenge. Solutions have included funded working groups at NCEAS for over 15 years, data repositories specific to ecology such as KNB, and a common hub to search for data at DataOne. Contemporary ecology is increasingly also best described by open and reproducible work, and few disciplines have adopted the use of r as extensively as ecology nor towards leveraging more open science such as r-open science. Big data machine learning is also being used to explore whether we can detect patterns in high dimensional data (Peters et al. 2014). Whilst ecology is a mashup of natural history and experimentalism, contemporary ecology is thus an even more literal mashup of the analog and digital representations of natural systems.
Biodiversity and Complexity
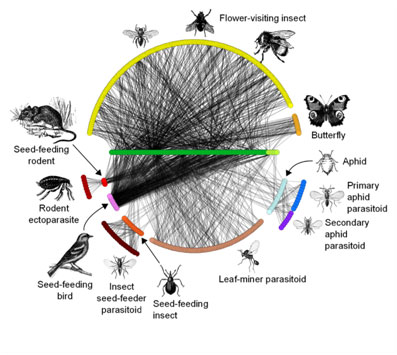 Biodiversity is an inherent driver of why many ecologists do what they do. We examine ecosystems with different species present and often seek to understand not only how they interact within one another and the environment but also why are there so many, so few, and different ones present. Biodiversity inspires us. Biodiversity challenges us. Biodiversity compels us to become more like other fields with big data on these patterns of differences. There are no shortages in challenges associated with measuring and defining biodiversity. There are challenges in linking the benefits of biodiversity to the function of ecosystems. There are also challenges in examining the complexity that comes hand-in hand with increasing the number of species that we include in our analyses and studies. One of the best examples of big data in ecology comes from the large-scale aggregation of species occurrences globally. Two common tools include GBIF and Calflora. These resource aggregations have big scope but are big data only in terms of variety but not volume nor velocity of their holdings. Two compelling examples of big data efforts to link the importance of process to local biodiversity include LTER and NEON. These networks overcome the challenge of variety of big data (and context as described above) by ensuring that protocols are aligned across the entire network and that common meta-data standards are adopted – at least within each network. More broadly, specific metadata tools for ecologists such as Morpho are used in and out of networks to encourage more facile connection and usage of data. Describing and mapping big data are the first challenge that additional funding can solve to provide the big data we need. Repositories exist and metadata standards are clearly defined and available for ecologists now. Incentives in terms of recognition and citations are also widely appreciated in ecology now too. Process diversity and links to species biodiversity are solved primarily through future-forward, aligned methods within networks of researchers as described above. Ecology also engenders the start-up spirit of science through less formal cooperatives such as Nut-net, TraitNet, Drought-Net, or the tireless work of our societies such as the ESA, INTECOL, or BES. In summary, the means via frameworks and repositories to aggregate existing data are present and rapidly evolving. Ongoing collection of new big data is also moving to aligned formal and informal networks to ensure that we can connect the biodiversity dots of species to place, pattern to process, and local knowledge to meaningful data.
Biodiversity is an inherent driver of why many ecologists do what they do. We examine ecosystems with different species present and often seek to understand not only how they interact within one another and the environment but also why are there so many, so few, and different ones present. Biodiversity inspires us. Biodiversity challenges us. Biodiversity compels us to become more like other fields with big data on these patterns of differences. There are no shortages in challenges associated with measuring and defining biodiversity. There are challenges in linking the benefits of biodiversity to the function of ecosystems. There are also challenges in examining the complexity that comes hand-in hand with increasing the number of species that we include in our analyses and studies. One of the best examples of big data in ecology comes from the large-scale aggregation of species occurrences globally. Two common tools include GBIF and Calflora. These resource aggregations have big scope but are big data only in terms of variety but not volume nor velocity of their holdings. Two compelling examples of big data efforts to link the importance of process to local biodiversity include LTER and NEON. These networks overcome the challenge of variety of big data (and context as described above) by ensuring that protocols are aligned across the entire network and that common meta-data standards are adopted – at least within each network. More broadly, specific metadata tools for ecologists such as Morpho are used in and out of networks to encourage more facile connection and usage of data. Describing and mapping big data are the first challenge that additional funding can solve to provide the big data we need. Repositories exist and metadata standards are clearly defined and available for ecologists now. Incentives in terms of recognition and citations are also widely appreciated in ecology now too. Process diversity and links to species biodiversity are solved primarily through future-forward, aligned methods within networks of researchers as described above. Ecology also engenders the start-up spirit of science through less formal cooperatives such as Nut-net, TraitNet, Drought-Net, or the tireless work of our societies such as the ESA, INTECOL, or BES. In summary, the means via frameworks and repositories to aggregate existing data are present and rapidly evolving. Ongoing collection of new big data is also moving to aligned formal and informal networks to ensure that we can connect the biodiversity dots of species to place, pattern to process, and local knowledge to meaningful data.
Summary

Photo from Chris Lortie.
Ecology will become increasingly responsible for the description of the basic interaction sets associated with big data from genes, global climate, and human transactions that relate to the environment. The historical limitation of ‘everything is context specific’ is best viewed as an outdated criticism of ecology because contemporary ecology commonly now leverages context directly. Context can provide us with a mechanism to examine mediation, changes in net interactions, and the relative importance of specific places versus broad-scale generic changes. Biodiversity is a charismatic, key element of ecology but defining and connecting differences between species in space and time is an ongoing challenge. This is increasingly resolved through open data, common repositories and shared search tools, and future-forward networks that ensure aligned data collection. These are only a few of the more topological challenges that ecologists face in working with larger sets of evidence and big data. We are also advancing use of novel data streams associated with context via citizen science participation in recording patterns locally and sharing globally such as the Breeding Bird Survey in many countries and in documenting biodiversity via imagery through iDigBio type collaborations. Ecology is an accessible discipline of science. Projects that include a broader audience are both challenge and solution to aggregating novel big data for natural systems. This is a clear way forward for effective, positive change in promoting the functioning of ecosystems because big data have perceived and real big value in society, and participation in the process of building big ecological data forces us to pay attention to changes in the quality of the ecological context we experience and the biodiversity of residents that share where we live.
Calling for Papers
In light of these big-data challenges and solutions facing ecology, GigaScience has launched and published its first papers in an open thematic series, “Data intensive science in ecology: reproducible science“; Guest Edited by Dr. Christopher Lortie, Dr. Noah Lottig, Dr. Mark Schildhauer, and Dr. Xin Zhou. This comprehensive and forward-looking series will highlight new advances, applications, and challenges, and serve to promote and improve data sharing and reproducibility in ecology science. We encourage the submission of Research Articles and Technical Notes, as well as Data Notes, which are papers that focus on the description of interesting datasets, curated and hosted in our database, GigaDB.
Potential topics for articles in this Data-Intensive Ecology series include, but are not limited to:
- Ocean research
- Big synthesis indices such as the Ocean Health Index and environmental impact indices
- Biodiversity including eco-genomics and metabarcoding
- Eco open science community, including new tools, software to make sense of big ecology data
- Macrosystems/Integrative ecology
- Limnology
- Terrestrial plant ecology
For more information, please email editorial@gigasciencejournal.com
References
- Chamberlain SA, Bronstein JL and Rudger, JA. How context dependent are species interactions? Ecology Letters 2014;17:881-890.
- Hampton SE, Strasser CA, Tewksbury JJ, Gram WK, Budden AE, Batcheller AL, Duke CS and Porter JH. Big data and the future of ecology. Frontiers in Ecology & the Environment. 2013;11:156-162.
- Lortie CJ and Bonte D. Zen and the art of ecological synthesis. Oikos. 2016;125:285-287.
- Nabout J, Gomes M, Machado K, Rocha CFD, Diniz-Filho J and Logares R. The Trends to Multi-Authorship and International Collaborative in Ecology Papers. Proceedings of ISSI. 2015.
- Peters DPC, Havstad KM, Cushing J, Tweedie C, Fuentes O and Villanueva-Rosales N. Harnessing the power of big data: infusing the scientific method with machine learning to transform ecology. Ecosphere. 2014;5:1-15.