RDA20 Plenary: A Decade of Data 2013-2023. Celebrating 10 years of the Research Data Alliance (RDA)
Gothenburg, Sweden played host to the Research Data Alliance (RDA) RDA20 plenary from March 20th to 24th 2023. A hybrid event with most sessions recorded and made available via the Whova app for registered participants. Recordings will be made available on Monday, 1 May 2023 to the wider community.
For the first in-person plenary since lockdown, the RDA celebrated its 10th year anniversary (this being a good 12 months for 10-year anniversaries). The RDA20 plenary promised to be something special. It delivered!
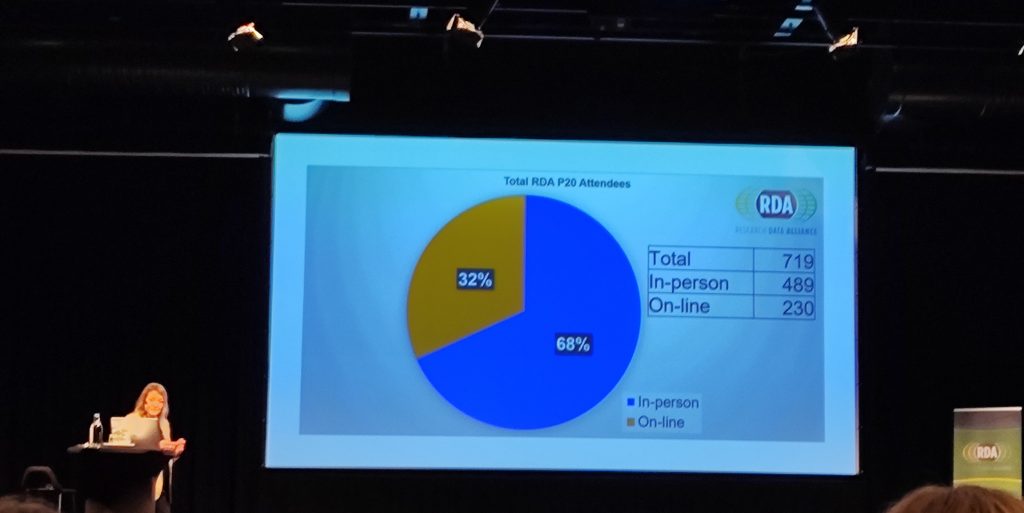
The day before the actual plenary started (Monday 20th) as well as the day after (Friday 24th), there were several co-located meetings being held, so effectively it was a 5 day meeting. For many of the attendees it was their first F2F meeting in 3 years due to the pandemic, so those people found it particularly hard work staying actively engaged.
We reconnected with our colleagues at DataCite on Monday at the DataCite connect meeting. Readers of this blog should know of our long-term membership and use of their identifiers in GigaDB.
The main plenary days followed a schedule of keynotes in the morning followed by parallel breakout sessions from mid-morning through to the end of the day. The organisers had helpfully provided a set of suggested pathways for attendees to use based on the theme(s) of interest; one suggestion I have to further improve this would be to include the days/times and rooms of the suggested sessions to aid navigation at the event
Here I highlight a small selection of the presentation that I found informative and interesting. The Practical Approaches to Tracking and Communicating the use of Research Data session provided a summary of the Data Usage Working Group output which recommends 5 things :
1: Data usage is complicated, while these complex areas will need to be resolved, the focus should remain on the adoption of minimal frameworks for counting data usage.
2: Utilizing the COUNTER Code of Practice for Research Data, and utilizing DataCite for aggregations.
3: There should be caution against defaulting to data metrics like a data impact factor.
4: Consider potential shortcomings, mitigations that can be made, and broader use cases for implementation to better understand usage types.
5: Close coordination with Scholix is recommended as usage and citation are closely tied together.
Matt Buys from DataCite followed with an update on the Make Data Count Initiative, of which our team member Scott Edmunds is on the Advisory Board of. Which is a stable framework, but requires a broader adoption to make it useful. Currently, we are in a slight chicken-and-egg situation with repositories reluctant to offer the data metrics until someone provides the specifications of what exactly should be provided. The funders are not pushing for anything specific about data usage partly because they don’t know what is possible. Authors still focussed on journal citation as a mechanism of reward, meaning they aren’t particularly motivated to push for data usage measuring.
One effort to jump-start the process is the Wellcome initiative to create a global corpus of data citations and data mentions. The initiative is gathering a corpus of references to published data within journal articles and pre-prints. It aims to provide a global set of measurable links that can be used to explore what is possible and what is useful in terms of data usage tracking.
Kelly Stathis (DataCite) presented the DataCite Usage Tracker (beta release). The goal of the tracker is to reduce the burden of implementing usage tracking on repositories. The general idea is that a repository embeds a small javascript in the landing page of the dataset. This sends a message to the DataCite usage tracker every time someone visits the page. In addition, another javascript can be embedded in a download confirmation page which then counts the number of downloads of that dataset. This is a beta service at the moment, and one that GigaDB intends to implement, so watch this space!
There were a number of sessions discussing software as research objects. Including presentations from FAIR4RS and DOME-ML, as well as CodeMeta. The latter is an attempt to standardise the way in which developers can share the metadata about their software and code. Essentially it is a JSON-LD schema that includes holders for all the important bits of information that a potential user (either human or computer) may require to use the software, e.g. the citation details, version number, dependencies, environment, the status of code, community links, etc…
It wasn’t all just presentation after presentation. Many of the sessions included panel discussions to engage with the audiences. The co-located workshops book-ending the meeting all included collaborative working sessions to move the groups forward towards their respective goals.

No meeting would be complete without networking events. RDA20 provided two such opportunities. First was the birthday celebration in the fabulous town hall (see Fig2). As well as the conference dinner which included live entertainment from the Chalmers University band-cum-circus act!? Think big brass band meets circus clowns, you had to see it to believe it.
All-in-all the meeting was a great success, a tribute to all those involved organising and participating in it. The next RDA installment will be International Data Week in Salzburg 23-26 October 2023.