Reflect, Enjoy, Do something! Lessons from the International Digital Curation Conference
Kevin Ashley’s (DCC director) closing remark at the IDCC (International Digital Curation Conference) 2024 meeting was “Reflect, Enjoy, Do something!”. Hopefully you will enjoy my doing something. The International Digital Curation Conference meeting in The Royal College of Surgeons, Edinburgh, 19-22 Feb 2024, marks their first in-person meeting for 4 years (and an even longer gap since we last attended). It was run as a hybrid meeting with >150 people in attendance at the venue and another 30 or so virtually via the Whova app.

On Monday 19th, the day prior to the main conference there were a series of digital curation workshops at the same venue. Workshop2 had the very descriptive title “Guidelines on transparent exposure of repository information: informing decisions of trustworthiness” (see the session notes) and contained 3 short talks followed by a 1 hour interactive exercise where participants were invited to complete a questionnaire on how a repository of their choice exposes information about itself, a sort of transparency assessment. While we at GigaScience Press (and specifically the GigaDB team who attended) endeavor to be at the forefront of FAIR and transparent open data publishing, the exercise did highlight some ways in which we could do better, and we will be taking action on those as soon as we can.
In Workshop 6 FAIR-by-design:Introducing Skills4EOSC and FAIR-IMPACT, much of the focus was on software metadata availability, and ways to enhance discoverability and transparency of research software.
The main event kicked off with a keynote by Ingrid Dillo, director at DANS (Data Archiving and Networked Services) in the Netherlands. Ingrid highlighted the need for transparency in research at all stages from funding and implementation through to publishing in order to (re)gain the trust of all actors, including the public (who fund much of the academic research). Her sentiments on the need for transparency were echoed throughout the meeting.
The majority of the meeting was conducted as 3 parallel sessions, which gives a greater breadth to the proceedings, but does mean its difficult to get involved in everything. Luckily, the sessions were all recorded and are available to participants via the Whova app for 8 weeks after the meeting, and then they will be made public.
Research Workflow Graphs – A Digital Curation Case Study from Materials Science
An insightful talk was provided by Ye Li (MIT) who collaborated with Crystallographers and Materials Scientists in an effort to categorise research workflows into digitally automated steps, partially automated steps, and manual steps. The core concept in Ye’s talk, which was entitled “Reproducible and Attributable Materials Science Curation Practices: A Case Study”, was to explore to what degree ‘wet lab’ researchers use automation and data sharing in their day-to-day activities.
From her Research Workflow Graph-based analysis, Ye highlighted some notable workflow characteristics, and these included email and portable media being used substantially for data storage, which highlighted a lack of centralised data storage. Ye also highlighted that collaboration networks are partitioned by project, and are thus an additional potential barrier to data sharing. Furthermore, there were extensive manual analytical steps used by Crystallographers and Materials Scientists involving, for example, microscopy, which are potentially scriptable and therefore could be automated.
Ye’s core recommendation for Materials Science researchers was to reduce manual data transfer and operations, and where possible to eliminate the use of multiple storage locations.
Trust and Transparency
With the overarching theme of Trust through transparency it’s hardly surprising that the word trust appears in a great number of the talk titles and abstracts, with 9 out of the 15 sessions including the words trust and/or transparency in the session title.
Lauren Collister, during her presentation on “A new tool to enhance transparency, discoverability and trust in open infrastructure” came out with the phrase “Trust is the new prestige”. I interpreted this to mean while previously everyone was aiming to be the most prestigious (publisher), now they want to be the most trusted (publisher). The tool she presented is designed to enhance discovery and uptake of open-source infrastructure tools, it is due to be launched in April 2024.
Genomic Diversity and Barriers to Clinical Translation
Latrice Landry (University of Pennsylvania) gave a thought-provoking talk entitled “Artificial Intelligence Assisted Curation of Population Groups in Biomedical Literature” which explored the lack of ancestral diversity in genomic databases. Latrice referred to her study from 2017, where Latrice and colleagues examined the populations included in genomic studies whose data were available in the Genome-Wide Association Study Catalog (NHGRI-EBI GWAS Catalog) and the database of Genotypes and Phenotypes (dbGAP). Latrice and colleagues found significantly fewer studies of African, Latin American, and Asian ancestral populations in comparison to European populations, with European cohorts representing 71% of genomics research cohorts across these public databases, whilst only representing 15% of the global population.
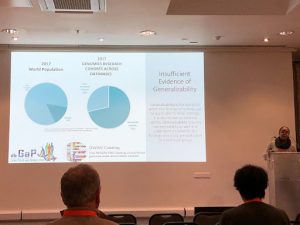
Latrice Landry reported on ancestral diversity in public genomic databases.
Latrice explained that the lack of ancestral diversity is “a barrier to clinical translation in clinical medicine”, and impacts on generalisability in genomic studies from public databases.
For more on ancestral diversity see our recent GigaBlog on Diversity, Ancestry, and the Tenacious Concept of Race.
On a tangential theme (studies involving human subjects) in another session, Devon Donaldson presented his preliminary findings looking into the transparency of data brokers providing electronic health record data. e-Health records are by necessity private, but there is a great deal of valuable research information held in them. Data brokers, usually embedded within a local research organization, can gain access to those records and provide snippets of data to researchers upon application with suitable safeguards in place to ensure no identifiable data are exposed. However, there is a huge amount of trust needed, by the researchers of the data broker, to write the correct query to sufficiently answer the research question. Devon showed that many researchers are hesitant to just accept a summary of results from a black-box style query of private data in this way, so his research aims to promote best practices in transparency, one such early finding is that just enabling the researchers to see the query code being run on the private data could go along way to building trust.
Metrics are still important, despite all the negativity around the use of Journal Impact Factors, the general feeling is that many actors still require a means to assess use, reuse and dissemination of research objects. With regards to data, the emerging best practice is the use of the “unique items”, as defined by projectCOUNTER, where by the count of accesses or downloads is only counted once within a session, for example if a user accesses an HTML version of the paper then decides to change to the PDF version, its counted as only 1 access item.
Of particular interest to me was the presentation by Dieuwertje Bloemen (KU Leuven) who presented how she and her team support a wide array of data publications in their institute. With a constant need to reiterate the work they do is to help not to judge the researchers! Also, due to the scale of data publications that they need to work with, they are now more focused on training rather than personal 1 to 1 assistance. This was due to a study they conducted on their own corpus, showing that ~23% of first-time submitters succeeded with only 1 round of review, whereas >70% of experienced submitters succeeded with only 1 round of review. This indicates that the researchers are able and willing to learn how to submit their data, so the move to training is likely to be more productive.
In the same vein, SpringerNatures’ Research Data team are no longer working directly with authors as much, instead focusing on training of Editorial staff for what to look for in the data availability statement (DAS). They started with BMC (formerly BioMed Central, our first co-publishers) staff who have been implementing open standards for a while, and while no solid evidence was provided they stated there has been an “improvement in compliance” in BMC publications since this training of their Editors.
Lars Vilhuber talked about work going on in the economics publishing area where the informatics parts of papers could be run in a “certified” environment and given a stamp of trustworthiness and the output logs published to increase transparency and trust without the need for multiple re-runs of software/code at large expense to either publishers or reviewers. Our collaborations with CODECHECK have tried to do something similar, so its good to see such moves increasingly used.
The final keynote presentation by Stavrina Dimosthenous (ROYCE), highlighted the need for greater work in the materials field to increase FAIRness, particularly the discoverability which is lacking due to the lack of inclusion of suitable metadata with studies and datasets. She also highlighted the need for suitable search mechanisms to achieve the F in FAIR.
The general feeling is that we are at a tipping point now where the majority of researchers are aware of the good curation practices and FAIR principles, they are just lacking the tools and training to implement them for themselves.
The International Digital Curation Conference will be back next year at a date and location yet to be announced! Please keep an eye on the DCC events page for future announcements.