Power to the People and Their Data – The Open Humans Way. Q&A with Bastian Greshake Tzovaras and Mad Price Ball
 In the data driven era, not only in research but in our day-to-day lives, people are creating more and more personal digitized data that enables human-participant research in social sciences and personalized medicine. However, with numerous data streams and types this raises concerns such as how to merge and share such data, as well as ethical problems.
In the data driven era, not only in research but in our day-to-day lives, people are creating more and more personal digitized data that enables human-participant research in social sciences and personalized medicine. However, with numerous data streams and types this raises concerns such as how to merge and share such data, as well as ethical problems.
Published today in GigaScience, is Open Humans, a collaborative effort led by Bastian Greshake Tzovaras and Mad Price Ball to present case studies and provide an open call for contributors to their community-based platform for participant led research. Having launched in 2015, this unique open source, community-centric platform has been featured in Forbes, Newsweek, Scientific American, and more. Here in one of our Author Q&A’s, Bastian Greshake Tzovaras (Director of Research) and Mad Price Ball (Executive Director) share a little history of Open Humans, as well as their thoughts on current challenges, such as social media scandals, and data restrictions.
How did the idea of Open Humans take shape? You were previously both involved in OpenSNP and the Personal Genome Project, so what does Open Humans bring beyond these efforts sharing personal genotype and phenotype information?
Open Humans was first founded in a nonprofit that had previously supported the PGP, and it’s an iteration that on the approach taken by the PGP and openSNP. They’re definitely connected ideas! Open Humans is based on lessons we learned.
The first big difference is that Open Humans offers a lot more privacy. Both openSNP and the Personal Genome Project take a rather radical approach to the sharing of personal data: Agree to make it all public and allow everyone to use the data, no questions asked. This is approach is very valuable as it removes the friction in wanting to use these data and allows the data to have the most impact. But the fact is also that this approach to data sharing isn’t for everyone: Not everyone is comfortable to put their data publicly out there. This is why Open Humans gives people control about which data to share with whom. So individuals can select which uses of their data they agree with and consent individually to having the data used for that project.
The second big difference between Open Humans on the one hand and the PGP and openSNP on the other is what kinds of data people can import and share. The PGP and openSNP have their focus on genetic data and phenotypic data. But we all collect so much more data about ourselves these days: GPS records of where we’ve been, our social media usage behaviour, our physical activity from all the wearable devices etc. Many of these data types are just as interesting as genetic data and often even more useful to the individual and for research.
What does participant-centered research enable that traditional research and healthcare systems currently doesn’t handle? Why should patients share their data in this way?
It’s important to recognize that research with people and their data isn’t a “zero sum game”: the same data can be involved in exploring a variety of questions. Including patient communities and other non-institutional opportunities is beneficial because these groups often prioritize questions, needs, and projects that are very different from the priorities traditional institutional research teams might investigate. Perhaps more importantly, these goals are often things people want to be part of. As a result, we’re unlocking more research than we had before, supporting innovation that would not otherwise happen.
You’ve both obviously drunk the cool-aid of carrying out participant-centered research on yourselves, so what types of data are you both collecting? What have you learnt about yourself from studying and sharing it?
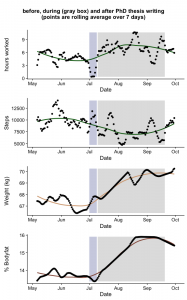
The effects of writing a PhD, Source: Bastian Greshake Tzovaras
BGT: Phew, I’m collecting really too much data to give a comprehensive list. Besides having multiple genotyping and exome sequencing data sets, I’ve been an extensive user of wearable devices for many years to collect things like physical activity, heart rate, sleep, body temperature, weight etc. I also have an extensive collection of my geo locations and then there’s also all the social media/digital device usage data such as my Twitter & Spotify usage and keeping track of which apps & websites I use when. The last fun thing I learned from my data is how unhealthy it was to finish my PhD. By visualizing my weight, physical activity and time spent working over time I could see that I easily gained 3 kilograms of weight during the last 2 ½ months of writing up my thesis (see blog post here)!
MPB: I feel like I’m a bit late to the game with self-tracking, but I’ve got two major themes going on right now that have been really useful for me. One is my diet: I’ve lost 25 kilograms since 2017 — boring maybe, but valuable for me! The continuous feedback of food logging and weight tracking have helped me. Also, more recently, I’ve gotten into mood tracking. It’s been very interesting to look back on my highs and lows — how long they last, and how things return to “average” in the end. I can also see my personal daily rhythm: starting high and drifting down each day. (I’ve always been more of a morning person!) Mood might relate to many other things — from personality to genetics to social media use– and it’s a great target for personal interventions we might be making to, literally, be happier people.
We are obviously also on the side of opening up data, but in a world of facebook scandals, ancestry websites being mined by law enforcement, and dystopian Chinese social credit systems, what do you say to critics of sharing your personal information in this way? Have you personally seen any examples of data sharing that have had negative consequences? And what steps have Open Humans taken to protect against these and address new legislative challenges like GDPR?
Sharing data can certainly be challenging and have negative consequences, especially when data is being made openly available. That’s why Open Humans takes a ‘private-by-default’ approach. All personal data stored in Open Humans is private by default and always accessible to the member themselves. And from there members can choose for example to share individual bits with a specific research study or even make individual datasets publicly available. This granular sharing helps in giving people much more control over who can use their data and for what ends. Similarly, we have our community review each new project/study that wants to run on Open Humans. In this way the community at large has control over which data can be used on Open Humans. This individual and community agency helps a lot in minimizing the dangers of sharing.
In terms of legislative challenges, we are actually big fans of the GDPR. The rights of data subjects under the GDPR – such as giving more control to users through specific consent, allowing them to access their data, ensuring data portability, etc. – are well aligned with our values and goals for Open Humans. This made implementing the GDPR rules rather straight-forward for us!
It was great Bastian visited us in Shenzhen to present at the BGI ICG Conference session we organised on Community Genomes (see video below). From traveling the world have you seen differences in how people interact with and share their medical data? To address this have you tried to make Open Humans compatible with different legal frameworks or more regionally specific data sources (e.g. geographically different social media platforms or wearable devices)?
I think there are definitely cultural differences in how people perceive the sharing of their personal data at large and how they navigate the balance of generating and using data and privacy issues around it. You can already see those differences between continental Europe and the UK/US: In my experience, people in continental Europe are much more concerned with protecting their privacy and are more likely to worry about the consequences of sharing their personal data or putting information on the internet compared to folks in the US or UK. So far we have not tried to target different legal frameworks in different ways. But by following the EU’s GDPR we’re complying with one of the most extensive regulations around the globe.
When it comes to regionally specific data sources like wearables or social networks that are popular in specific areas, we haven’t specifically tried to implement those into Open Humans yet. This is largely due to the fact that it is not easy to build tools to import data from devices that one doesn’t have access to personally. But as Open Humans is a modular ecosystem it allows anyone to build and provide a data importing project for their preferred regional wearables or social networks! I’ve people are motivated to build something like this we’re always happy to provide support in how to connect to the Open Humans APIs.
References
Greshake Tzovaras B, Angrist M, Arvai K, Dulaney M, Estrada-Galiñanes V, Gunderson B, Head T, Lewis D, Nov O, Shaer O, Tzovara A, Bobe J, Price Ball M. Open Humans: A platform for participant-centered research and personal data exploration. GigaScience. 2019. https://doi.org/10.1093/gigascience/giz076.
Open Humans. https://www.openhumans.org/