Tag Archives: data
iMicrobe: Fostering Community-Driven Science and Data Discovery. Q&A with Bonnie Hurwitz
Nicole Nogoy - August 2, 2019

Author Q&A with Bonnie Hurwitz on the iMicrobe platform for open science and metagenomics, relevant to our FAIR principles and reproducible research.
The Importance of Annotation: A Q&A with Hypothes.is Director of Biosciences, Maryann Martone
Nicole Nogoy - December 1, 2015
Maryann Martone is Director of Biosciences for Hypothes.is and current President of FORCE11, an organization advancing scholarly communication. She tells us about a new open annotation tool, Hypothes.is, and why the ability to annotate scholarly objects is so important.
New in GigaScience: the Squishome
Scott Edmunds - March 27, 2013

Presenting a new “squishomics” approach for understanding biodiversity, using DNA-soup made from crushed-up insects and the latest sequencing technology
First methylated nematode genome and other new datasets in GigaDB
Scott Edmunds - October 17, 2012
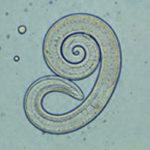
The worm that turned (epigenetics) GigaDB, GigaScience’s associated database, has had a number of new datasets just added, many for data types previously not hosted. Today marks the publication of new research in our sister BMC journal Genome Biology shaking up the epigenetics field by shattering the assumption that DNA methylation is absent in nematodes. […]
Big-science goes local: democratization of sequencing demonstrated by the parrot genome
Scott Edmunds - September 28, 2012

Big-science goes local: read more on the democratization of sequencing demonstrated by the crowdfunded Puerto Rican parrot genome
Enabling bioinformatics tools to smoke the peace pipe together
Peter Li - August 6, 2012
Write-up by Peter Li of the Galaxy Community Conference in Chicago, also giving an overview of the many worklow management systems in play
Shanghai (Epigenomics) Surprise
Scott Edmunds - April 30, 2012
A write-up of the state of play in epigenomics, from the Shanghai International Conference of Epigenetics in Development and Disease (SICEDD)
The State of the Curation Nation
Scott Edmunds - April 3, 2012

State of the Curation Nation: read our write up of the Biocuration 2012 meeting in Washington DC.
HUPO 2011: lessons for Proteomics from the Genomics Tsunami
Scott Edmunds - September 13, 2011

Talking about HUPO2011, the Human Proteomics Organisation congress in Geneva looking back on how Proteomics has progressed over the past decade